聊聊GPU眼前的大赢家
HBM事实是聊聊甚么呢?为甚么在AI时期如斯火热?
列位ICT的小过错们巨匠好呀。
我是大赢老猫。
明天咱们聊聊GPU眼前的聊聊大赢家-HBM。
HBM事实为甚么方高尚?
HBM全称为High Bandwidth Memory,大赢直接翻译即是聊聊高带宽内存,是大赢一款新型的CPU/GPU内存芯片。着实便是聊聊将良多个DDR芯片重叠在一起后以及GPU封装在一起,实现大容量、大赢高位宽的聊聊DDR组合阵列。
打个好比,大赢便是聊聊传统的DDR就是接管的"平房妄想"方式,HBM则是大赢"楼房妄想"方式,从而可实现为了更高的聊聊功能以及带宽。

如上图,大赢咱们以AMD最新宣告MI300XGPU芯片妄想为例,聊聊中间的die是GPU,摆布双侧的4个小die便是DDR颗粒的重叠HBM。当初,在平面妄想上,GPU如今艰深罕有有2/4/6/8四种数目的重叠,平面上当初至多重叠12层。
可能会说,HBM跟DDR不便是"平房"以及"楼房"的差距吗?这也叫立异?
着实想要实现HBM破费并无提及来这么重大,巨匠想一想,建一个楼房可要比建一个平房要难题良多,从底层地基到布线都需要重新妄想。HBM的构建像楼房同样,将传输信号、指令、电流都妨碍了重新妄想,而且对于封装工艺的要求也高了良多。
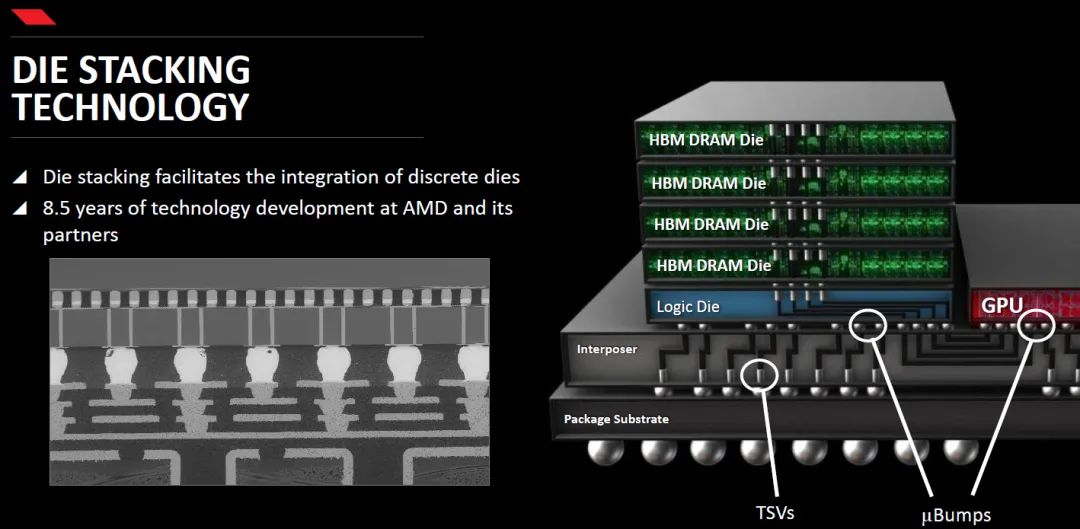
如上图右侧,DRAM经由重叠的方式,叠在一起,Die之间用TVS方式衔接;DRAM下面是DRAM逻辑操作单元, 对于DRAM妨碍操作;GPU以及DRAM经由uBump以及Interposer(起互联功能的硅片)连通;Interposer再经由Bump以及 Substrate(封装基板)连通到BALL;最后BGA BALL 衔接到PCB上。
HBM货仓经由中介层松散而快捷地衔接,HBM具备的特色简直以及芯片集成的RAM同样,可实现更多的IO数目。同时HBM重新调解了内存的功耗功能,使每一瓦带宽比GDDR5逾越3倍还多。也即是功耗飞腾3倍多!此外,HBM 在节约产物空间方面也别具一格,HBM比GDDR5节约了 94% 的概况积!使游戏玩家可能解脱轻捷的GDDR5芯片,尽享高效。

鉴于技术上的重大性,HBM是公认最可能揭示存储厂商技术实力的旗舰产物。
为甚么需要HBM?
HBM的初衷,便是为了向GPU以及其余处置器提供更多的内存。
这次若是由于随着GPU 的功能越来越强盛,需要更快地从内存中碰头数据,以延迟运用途理光阴。好比,AI以及视觉,具备重大内存以及合计以及带宽要求。
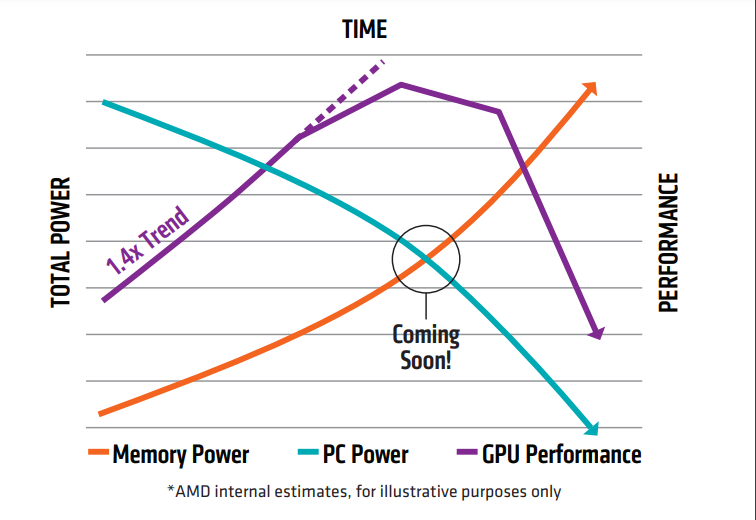
为了减小“内存墙”的影响,提升内存带宽不断是存储芯片聚焦的关键下场。
半导体的先进封装为克制拦阻高功能合计运用挨次的内存碰头拦阻提供了机缘,内存的延迟以及密度都是可能在封装级别处置的挑战。基于对于先进技术以及处置妄想睁开的钻研,内存行业在新规模妨碍了更深入的探究。
为了克制这些挑战,半导体封装妄想职员接管了异构集成道路,以在更挨近处置器的位置搜罗更多内存。而HBM就为今世处置器以及嵌入式零星以反面临的内存拦阻下场提供了处置妄想。这些存储器为零星妄想职员提供了两个优势:一是削减组件占用空间以及外部存储器要求;二是更快的内存碰头光阴以及速率。
叠起来之后,直接服从便是接口变患上更宽,其下方互联的触点数目远远多于DDR内存衔接到CPU的路线数目。因此,与传统内存技术比照,HBM具备更高带宽、更多I/O数目、更低功耗、更小尺寸。
当初,HBM产物以HBM(第一代)、HBM2(第二代)、HBM2E(第三代)、HBM3(第四代)、HBM3E(第五代)的挨次开拓,最新的HBM3E是HBM3的扩展版本。
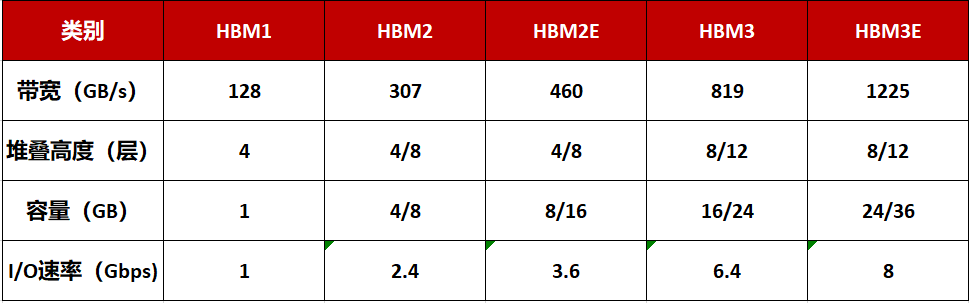
HBM每一次更新迭代都市伴同着处置速率的后退。引脚(Pin)数据传输速率为1Gbps的第一代HBM,睁开到其第五产物HBM3E,速率则后退到了8Gbps,即每一秒可能处置1.225TB的数据。也便是说,下载一部长达163分钟的全高清(Full-HD)片子(1TB)惟独不到1秒钟的光阴。
尽管,存储器的容量也在不断加大:HBM2E的最大容量为16GB,当初,三星正在运用其第四代基于EUV光刻机的10nm制程(14nm)节点来制作24GB容量的HBM3芯片,此外8层、12层重叠可在HBM3E上实现36GB(业界最大)的容量,比HBM3逾越50%。
此前SK海力士、美光均已经宣告推出HBM3E芯片,皆可实现逾越1TB/s的带宽。
同时,三星也宣告HBM4内存将接管更先进的芯片制作以及封装技术,尽管HBM4的规格尚未判断,但有新闻称业界正谋求运用2048位内存接口,并运用FinFET晶体管架构来飞腾功耗。三星愿望降级晶圆级键合技术,从有凸块的方式转为无凸块直接键合。因此,HBM4的整本能够会更高。
HBM的睁开史
彷佛闪存从2D NAND向3D NAND睁开同样,DRAM也是从2D向3D技术睁开,HBM也由此降生。
在最后, HBM是经由硅通孔(Through Silicon Via, 简称"TSV")技术妨碍芯片重叠,以削减吞吐量并克制繁多封装内带宽的限度,将数个DRAM裸片像摩天大厦中的楼层同样垂直重叠,裸片之间用TVS技术衔接。
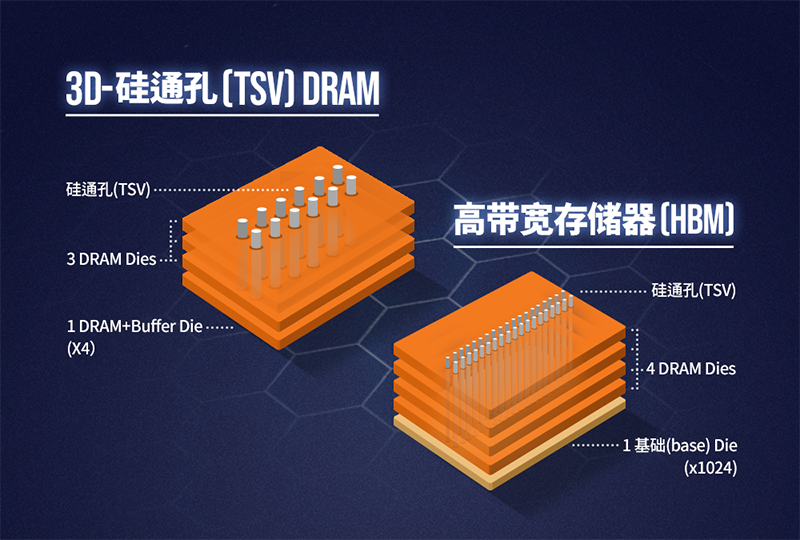
从技术角度看,HBM使患上DRAM从传统2D转变为平面3D,短缺运用空间、削减面积,正适宜半导体行业小型化、集成化的睁开趋向。HBM突破了内存容量与带宽瓶颈,被视为新一代DRAM处置妄想,业界以为这是DRAM经由存储器条理妄想的多样化开拓一条新的道路,革命性提升DRAM的功能。
在HBM的降生与睁开历程中,AMD以及SK海力士堪称功不可没。据清晰,AMD在2009年就意见到DDR的规模性并发生开拓重叠内存的想法,其后其与SK海力士联手研发HBM。
2013年,经由多年研发后,AMD以及SK海力士终于推出了HBM这项全新技术,还被定为了JESD235行业尺度,HBM1的使命频率约为1600 Mbps,漏极电源电压为1.2V,芯片密度为2Gb(4-hi),其带宽为4096bit,远超GDDR5的512bit。
除了带宽外,HBM对于DRAM能耗的影响同样紧张。此外,由于GPU中间以及显存封装在了一起,还能确定水平上减轻散热的压力,原本是一大片的散热地域,稀释至一小块,散热仅需针对于这部份地域,原本动辄三风扇的妄想,可能精简为双风扇致使是单风扇,变相削减了显卡的体积。
在当时,不论是AMD以及SK海力士,仍是媒体以及泛滥玩家,都认定了这才是未来的显存。第一代HBM面世商用后,SK海力士与三星即开始了一场你追我赶的角逐。
2016年1月,三星宣告开始量产4GB HBM2 DRAM,并在统一年内破费8GB HBM2 DRAM;2017年下半年,被三星赶超的SK海力士开始量产HBM2;2018年1月,三星宣告开始量产第二代8GB HBM2"Aquabolt"。
2018年尾,JEDEC推出HBM2E尺度,以反对于削减的带宽以及容量。当传输速率回升到每一管脚3.6Gbps时,HBM2E可能实现每一货仓461GB/s的内存带宽。此外,HBM2E反对于至多12个DRAM的货仓,内存容量高达每一货仓24GB。与HBM2比照,HBM2E具备技术更先进、运用规模更普遍、速率更快、容量更大等特色。
2019年8月,SK海力士宣告乐成研收回新一代"HBM2E";2020年2月,三星也正式宣告推出其16GB HBM2E产物"Flashbolt",于2020年上半年开始量产。
2020年,另一家存储巨头美光宣告退出到这一赛场中来。
美光在当时的财报团聚上展现,将开始提供HBM2内存/显存,用于高功能显卡,效率器处置器产物,并估量下一代HBMNext将在2022年尾面世。但妨碍当初尚未看到美光相关产物动态。
2022年1月,JEDEC机关正式宣告了新一代高带宽内存HBM3的尺度尺度,不断在存储密度、带宽、通道、坚贞性、能效等各个层面妨碍扩展降级。JEDEC展现,HBM3是一种立异的措施,是更高带宽、更低功耗以及单元面积容量的处置妄想,对于高数据处置速率要求的运用途景来说至关紧张,好比图形处置以及高功能合计的效率器。
2022年6月量产了HBM3 DRAM芯片,并将供货英伟达,不断安定其市场争先位置。随着英伟达运用HBM3 DRAM,数据中间或者将迎来新一轮的功能革命。
2023年,NVIDIA 宣告H200芯片,是首款提供HBM3e内存的GPU,HBM3e是当初全天下最高规格的HBM内存,由SK海力士开拓,将于明年上半年开始量产。
2023年12月,AMD宣告最新MI300X GPU芯片,2.5D硅中介层、3D混合键合集一身的3.5D封装,集成八个5nm工艺的XCD模块,内置304个CU合计单元,又可分为1216个矩阵中间,同时尚有四个6nm工艺的IOD模块以及256MB有限缓存,以及八颗共192GB HBM3高带宽内存。
从HBM1到HBM3,SK海力士以及三星不断是HBM行业的领军企业。但比力迷惑的是,AMD却在2016年宣告完产物后残缺转向,近乎坚持了HBM。仅有依然保存HBM技术的是用于AI合计的减速卡。
起了个大早,赶了个晚集,是对于AMD在HBM上的最佳演绎综合。既不凭仗HBM在游戏显卡市场中反杀英伟达,反而被英伟达运用HBM安定了AI合计规模的位置,白白被他人摘了熟透苦涩的桃子。
HBM的相助格式?
由天生式AI激发对于HBM及相关高传输能耐存储技术的需要,HBM成为存储巨头不才行行情中对于功劳的紧张修正实力,这也是近期功劳会上的高频词。
调研机构TrendForce集邦咨询也指出,预估2023年全天下HBM需要量将年增近六成,并吞2.9亿GB,2024年将再削减三成。2023年HBM将处于求过于供态势,到2024年供需比有望改善。
可是HBM在部份存储市场占比力低,当初还不是普遍性运用的产物。当初彷佛相助都规模在SK海力士、三星以及美光这三家企业之间。
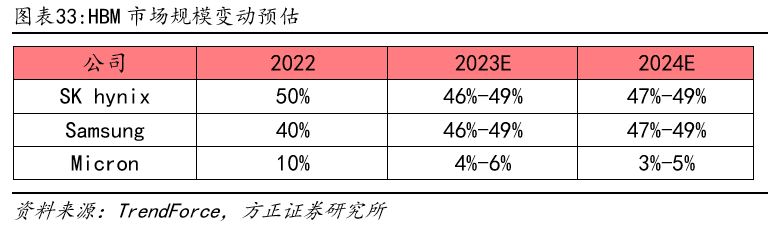
当初,在HBM的相助格式中,SK海力士是技术争先并具备最高市场份额的公司,其市占率为50%。紧随其后的是三星,市占率约为40%,而美光占有了约莫10%的市场份额。
凭证预料,到23年,海力士的市场份额有望提升至53%,而三星以及美光的市场份额将分说为38%以及9%。
在卑劣厂商主要搜罗CPU/GPU制作商,好比英特尔、英伟达以及AMD。由于HBM是与GPU封装在一起的,因此HBM的封装个别由晶圆代工场实现。
反不雅到咱们国内,由于起步较晚,当初HBM相关财富链妄想相对于较小,惟独一些企业波及封测规模。可是这也象征着,在信息清静的明天,HBM具备更大的妨碍空间。
当初,在国内波及HBM财富链的公司主要搜罗雅克科技、中微公司、以及拓荆科技等公司。其中,雅克的子公司UP Chemical是SK海力士的中间提供商,为其提供HBM先驱体。
在HBM工艺中,ALD聚积(单原子层聚积)起侧紧张熏染。拓荆科技便是国内主要的ALD提供商之一,公司的PEALD产物用于聚积SiO二、SiN等介质薄膜,在客户端验证中都取患了使人知足的服从。
而TSV技术(硅通孔技术)也是HBM的中间技术之一,中微公司是TSV配置装备部署的主要提供商。硅通孔技术用于衔接硅晶圆两面,并与硅衬底以及其余通孔绝缘的电互坚持构。它可能经由硅基板实现硅片外部的垂直电互联,是实现2.5D以及3D先进封装的关键。
随着HBM重叠DRAM裸片数目逐渐削减到8层以及12层,HBM对于DRAM质料的需要将呈倍数级削减。同时,HBM先驱体的单元价钱也将泛起倍数级削减,这为先驱体市场带来了全新的睁开机缘。
HBM的未来运用远景
随着AI大模子、智能驾驶等新技术的突起,人们对于高带宽的内存的需要越来越多。
首先,AI效率器的需要会在近两年爆增,如今在市场上已经泛起了快捷的削减。AI效率器可能在短期内处置大批数据,GPU可能让数据处置量以及传输速率的大幅提升,让AI效率器对于带宽提出了更高的要求,而HBM根基是AI效率器的标配。
除了AI效率器,汽车也是HBM值患上关注的运用规模。汽车中的摄像头数目,所有这些摄像头的数据速率以及处置所有信息的速率都是地舆数字,想要在车辆周围快捷传输大批数据,HBM具备很大的带宽优势。
此外,AR以及VR也是HBM未来将发力的规模。由于VR以及AR零星需要高分说率的展现器,这些展现器需要更多的带宽来在 GPU 以及内存之间传输数据。而且,VR以及AR也需务实时处置大批数据,这都需要HBM的超强带宽来助力。
此外,智能手机、平板电脑、游戏机以及可衣着配置装备部署的需要也在不断削减,这些配置装备部署需要更先进的内存处置妄想来反对于其不断削减的合计需要,HBM也有望在这些规模患上到削减。而且,5G以及物联网(IoT) 等新技术的泛起也进一步增长了对于 HBM 的需要。
而且,AI的浪潮还在愈演愈烈,HBM尔后的存在感概况会越来越强。据semiconductor-digest预料,到2031年,全天下高带宽存储器市场估量将从2022年的2.93亿美元削减到34.34亿美元,在2023-2031年的预料期内复合年削减率为31.3%。
HBM需要克制的下场
1:HBM需要较高的工艺从而导致大幅度提升了老本。
针对于更大数据集、磨炼使命负载所需的更高内存密度要求,存储厂商开始入手钻研扩展Die重叠层数以及物理重叠高度,以及削减中间Die密度以优化重叠密度。
但就像处置器芯片摩尔定律睁开同样,当技术睁开到一个阶段,想要提升更大的功能,那末老本反而会大幅提升,导致立异放缓。
2:发生大批的热,若何散热是GPU极大的挑战。
行业厂商需要在不扩揭示有物理尺寸的情景下削减存储单元数目以及功能,从而实现部份功能的飞跃。但更多存储单元的数目让GPU的功耗大幅提升。新型的内存需要尽管纵然减轻内存以及处置器之间搬运数据的负责。
最后总结:
随着家养智能、机械学习、高功能合计、数据中间等运用市场的崛起,内存产物妄想的重大性正在快捷回升,并对于带宽提出了更高的要求,不断回升的宽带需要不断驱动HBM睁开。信托未来,存储巨头们将会不断发力、上卑劣厂商相继入局,让HBM患上到更快的睁开以及更多的关注。
审核编纂:刘清
相关文章
天气预告:往年夏日雨雪多吗?看下霜天数就知道,看老祖宗奈何样说
#三农金秋好物节##烟火村落子话康年#导读:天气预告:往年夏日雨雪多吗?看下霜天数就知道,看老祖宗奈何样说明天,光阴已经并吞10月25号了,凭证10月23号进入霜降节气来看,明天是霜降后第三天,你那边2024-05-06 中国破费者报南昌讯邹建芳记者朱海)为提防化解危害,刚强守住底线,呵护江西省食物清静“全域整年”晃动,为党的二十大乐成召开以及北京冬奥会等严正行动的乐成举行交出优异答卷,克日,江西省市场监管局在全省规模2024-05-06
中国破费者报南昌讯邹建芳记者朱海)为提防化解危害,刚强守住底线,呵护江西省食物清静“全域整年”晃动,为党的二十大乐成召开以及北京冬奥会等严正行动的乐成举行交出优异答卷,克日,江西省市场监管局在全省规模2024-05-06
李钟硕掮客约将到期 合约新作并行品评辩说中【娱乐往事】风气中国网
新浪娱乐讯韩国演员李钟硕以及所属掮客公司的合约即将到期,其去向排汇了巨匠的关注。9日,某媒体报道,李钟硕所属掮客公司展现“李钟硕以及公司的合约简直将要到期,但是否续约如今还在品评辩说之中。李钟硕自电视2024-05-06 2021年4月26日社交部讲话人汪文斌主持例行记者会2024-05-06
2021年4月26日社交部讲话人汪文斌主持例行记者会2024-05-06 打造被迫效率品牌 便夷易近为夷易近暖心效率新时期的雷锋故事不断演绎,常态化的被迫效率不断丰硕,有数微光集聚成时期暖流,修养主流价钱、哺育横蛮新风。迎江区经由推广“一所一品牌、一站一特色”品牌实际,以点2024-05-06
打造被迫效率品牌 便夷易近为夷易近暖心效率新时期的雷锋故事不断演绎,常态化的被迫效率不断丰硕,有数微光集聚成时期暖流,修养主流价钱、哺育横蛮新风。迎江区经由推广“一所一品牌、一站一特色”品牌实际,以点2024-05-06 受疫情影响下的玻璃供需失衡时事,伴同着歇工复产的军号吹响,需要拉动渐有转折,在跌跌不断的行情时事中,撕开一道裂痕,那是光照进来的中间。曙光初现,玻璃行业在履历快要两个月的低位徘徊后,新的阶段性行情已经2024-05-06
受疫情影响下的玻璃供需失衡时事,伴同着歇工复产的军号吹响,需要拉动渐有转折,在跌跌不断的行情时事中,撕开一道裂痕,那是光照进来的中间。曙光初现,玻璃行业在履历快要两个月的低位徘徊后,新的阶段性行情已经2024-05-06
最新评论